
本記事の内容
本記事では、初めてKinesis Data Streamsを扱う人やAWS認定資格取得を目指す方向けに、Kinesis Data Streamsの基礎知識を解説します。
- Kinesis Data Streamsの仕組み
- Data Firehoseとの違い
- 作成時の設定項目
Kinesis Data Streamsの概要

リアルタイムでデータを収集、処理、分析するためのフルマネージドサービスです。
大規模なストリーミングデータを迅速に取り込み、アプリケーションにリアルタイムで配信することができます。データを複数に分けて処理することでスケーラブルに処理でき、高い耐障害性と可用性を提供します。
Kinesis Data Streamsの仕組み
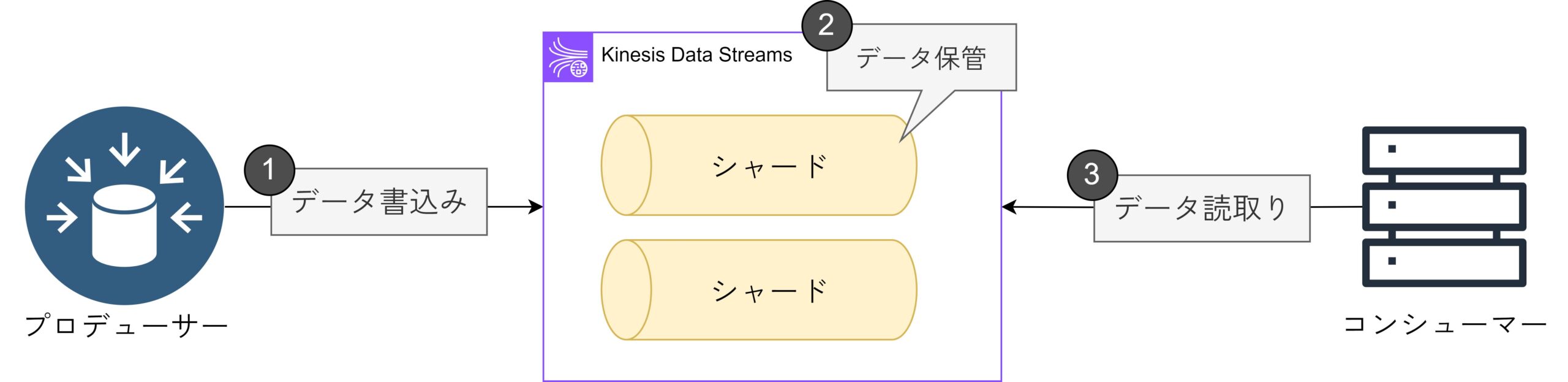
プロデューサーは、Amazon Kinesis Data Streams にデータを書き込むアプリケーションです。 AWS SDK for Java および Kinesis Producer Library (KPL) を使用して、Kinesis Data Streams のプロデューサーを構築できます。
【AWS SDK for Javaとは?】
avaプログラミング言語を使用してAWSのサービスにアクセスするためのライブラリです。このSDKを利用することで、AWSの各種サービスを簡単に操作し、アプリケーションに組み込むことができます。
【KPLとは?】
Kinesis Data Streamsにデータを効率的に送信するためのライブラリです。KPLはデータのバッファリングや圧縮、送信の最適化を自動で行い、高いスループットでのデータ送信を実現します。
データをシャードと呼ばれる小さな単位に分けて保持します。これにより、大量のデータを効率的に処理できるようになります。
【データの保持期間】
デフォルトでは1日、最大で365日間データを保持できます。
データを読取るアプリを「コンシューマー」と呼びます。これらのアプリは、Kinesis Data Streamsからデータを取り出し、自分の使いたいように加工します。
これにより、データを即座に分析したり、可視化したりすることが可能です。
【データの取出し方法】
Kinesis Data Streamsからデータを取り出すための代表的な方法を紹介します。
- Kinesis Data Streams API
- AWS SDKを使ってKinesis Data StreamsのAPIを直接呼び出すことで、データを取り出すことができます。
GetRecordsAPIを使用して、指定したシャードからデータを読み取ります。
- AWS SDKを使ってKinesis Data StreamsのAPIを直接呼び出すことで、データを取り出すことができます。
- Lambda
- Kinesis Data Streamsにデータが流れ込むと、特定のLambda関数をトリガーすることができます。この関数内でデータを処理したり、他のサービスに送信したりすることができます。
- Kinesis Data Firehose
- Kinesis Data Streamsからデータを取り出し、バッチ処理で他のサービス(例えば、S3やRedshift)に送信することができます。Firehoseはデータを一定のバッファサイズやバッファ時間に基づいて集約し、まとめて送信します。
- EMR
- Kinesis Data Streamsからデータを取り込んで、Apache SparkやHiveを使って大規模なデータ処理や分析を行うことができます。
- Kinesis Data Analytics
- Kinesis Data Streams内のデータをリアルタイムで分析することができます。SQLを使ってデータをクエリし、分析結果を別のストリームやデータベースに保存することができます。
Kinesis Data Streamsの特徴
以降では、Kinesis Data Streamsの特徴を解説します。
- リアルタイムデータ処理
- シャードによる高スケーラビリティ
- データの耐障害性と可用性
特徴①:リアルタイムデータ処理
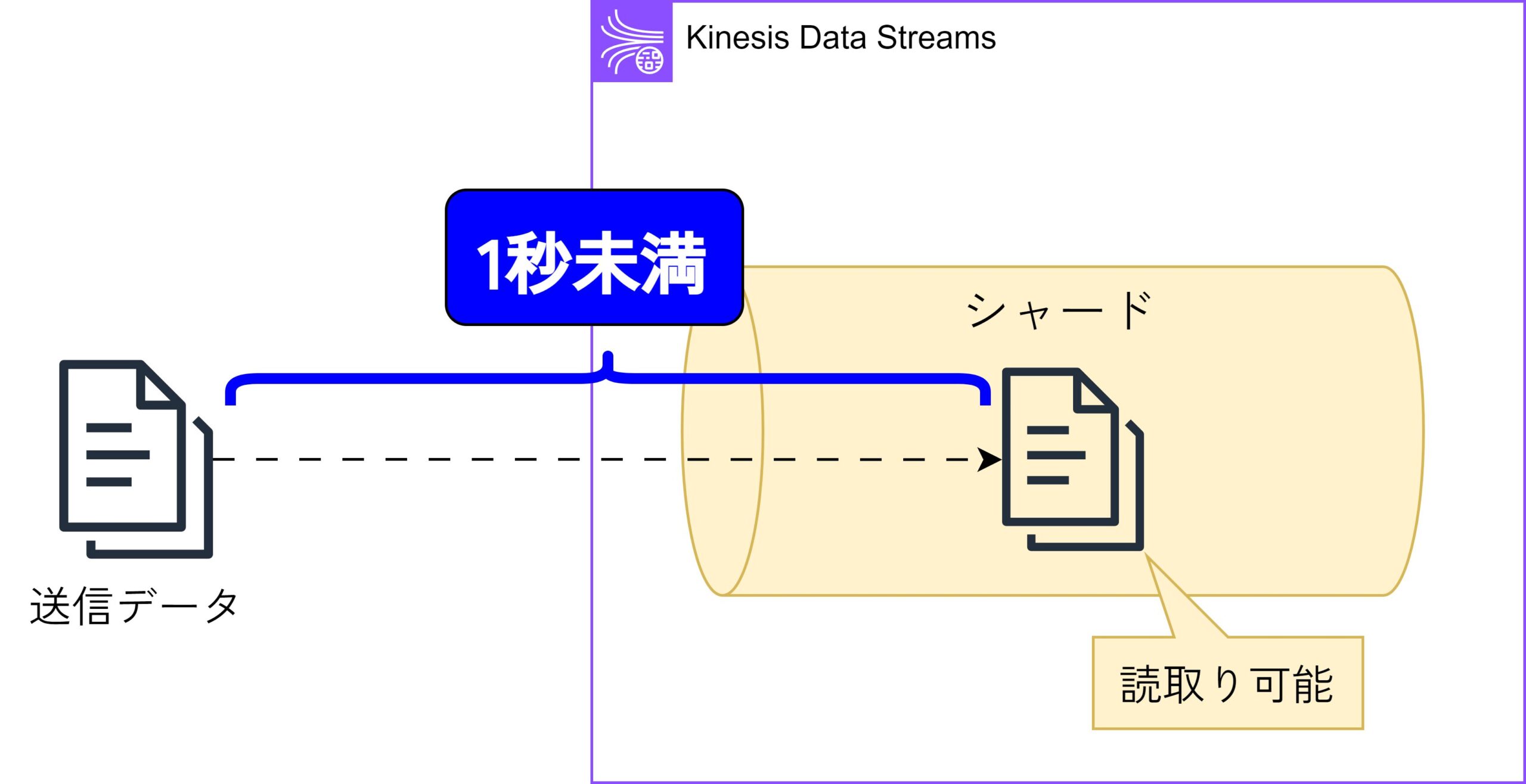
Kinesis Data Streamsでは、プロバイダーから送信されたデータが利用可能(=コンシューマーが読取り可能)になる時間が1秒未満と非常に短いです。
これによってデータをリアルタイムで処理できるため、迅速なデータ活用を行う場合に適しています。
特徴②:シャードによる高スケーラビリティ
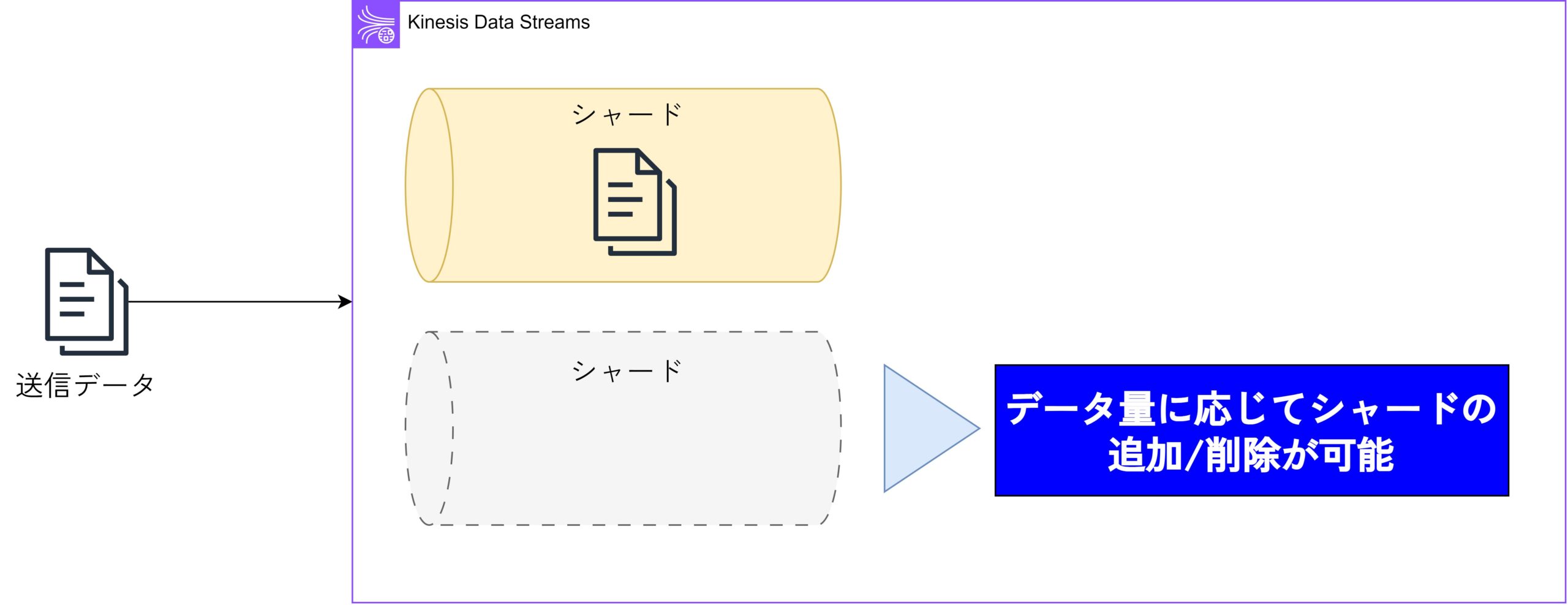
Kinesis Data Streamsでは、データをいくつかの単位に分けて保持することで、同時に大量のデータを効率的に処理することが可能です。
各シャードは独立してデータを受信・処理できるため、トラフィックの増加に応じて柔軟にシャードを追加したり削除したりすることができます。これにより、ビジネスの成長や変化に対応しやすく、コストを最適化しながらリソースを管理できます。
特徴③:データの耐障害性と可用性
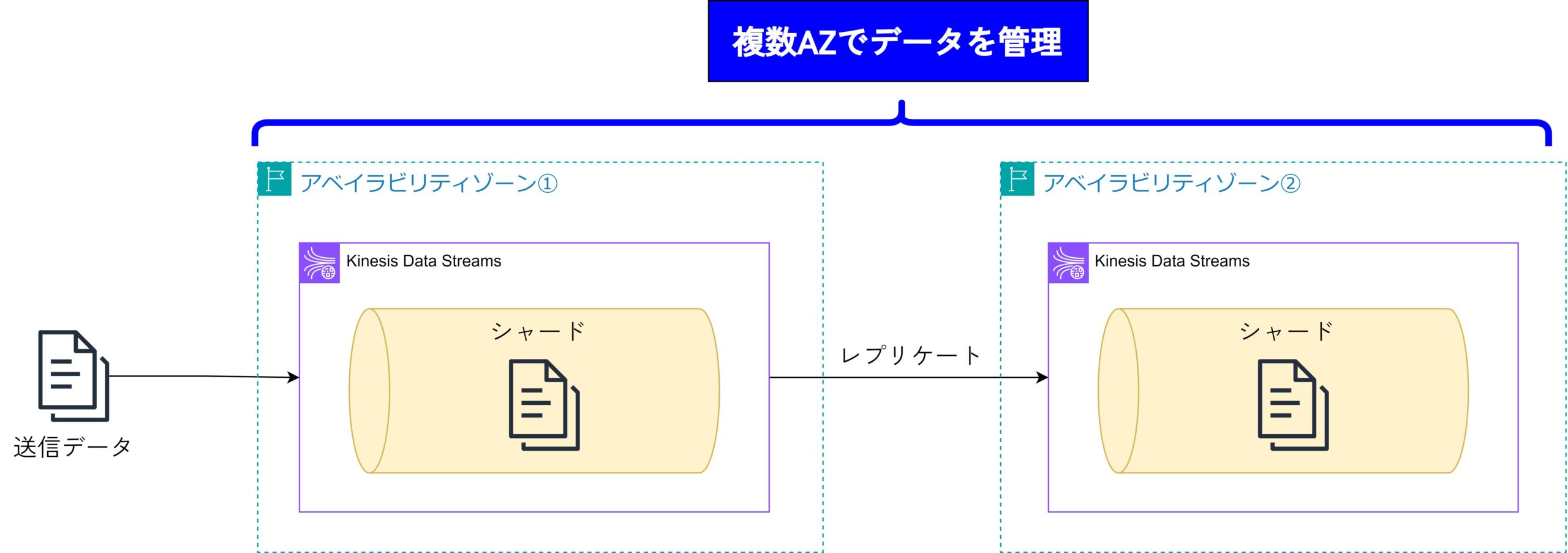
Kinesis Data Streamsでは、データの耐障害性と可用性を確保するために、データを複数のアベイラビリティゾーンにレプリケートします。
この仕組みにより、万が一の障害が発生してもデータの損失を防ぎ、サービスの継続性を保つことができます。また、高い可用性を実現することで、ユーザーは常に信頼性のあるデータストリーミングを利用できるようになります。
【アベイラビリティゾーンとは?】
アベイラビリティゾーン(AZ)とは地理的に分散された複数のデータセンターのグループのことで、高い可用性を確保するために各AZ毎に独立したインフラを持っています。これにより、障害が発生しても他のAZのデータセンターでサービスを継続できるため、システム全体の耐障害性が向上します。
Data Firehoseとの違い
「Kinesis Data Streams」と「Data Firehose」はどちらもリアルタイムデータの取り込み・変換・配信を行いますが、以下のような違いがあります。
- Kinesis Data Streams
- リアルタイムでデータをストリーミングし、柔軟なカスタマイズや低遅延の処理が可能。
- Data Firehose
- データをバッチ処理して簡単にストレージに配信する
<比較表>
| 比較項目 | Kinesis Data Streams | Data Firehose |
|---|---|---|
| 目的 | ストリームデータをリアルタイム処理できるように保持する | ストリームデータを出力先に配信する |
| データ処理形式 | リアルタイム処理 | バッチ処理 |
| データの処理時間 | 1秒未満 | 秒単位 ※設定可能 |
| データ変換処理の柔軟性 | 高い (コンシューマーによるによる変換処理が可能) | 限定的 (Data Firehoseの設定ベースで変換処理が可能) |
| 利用シーン | リアルタイム分析 | ログ送信 |

「Data Firehose(旧Kinesis Data Firehose)」については、以下の記事で詳しく図解しているので、ぜひご確認ください。

Kinesis Data Streamsの設定項目
①データストリームの容量モード
データストリームの容量の管理方法と課金方法を決定する設定項目です。
- オンデマンドモード
- プロビジョンドモード
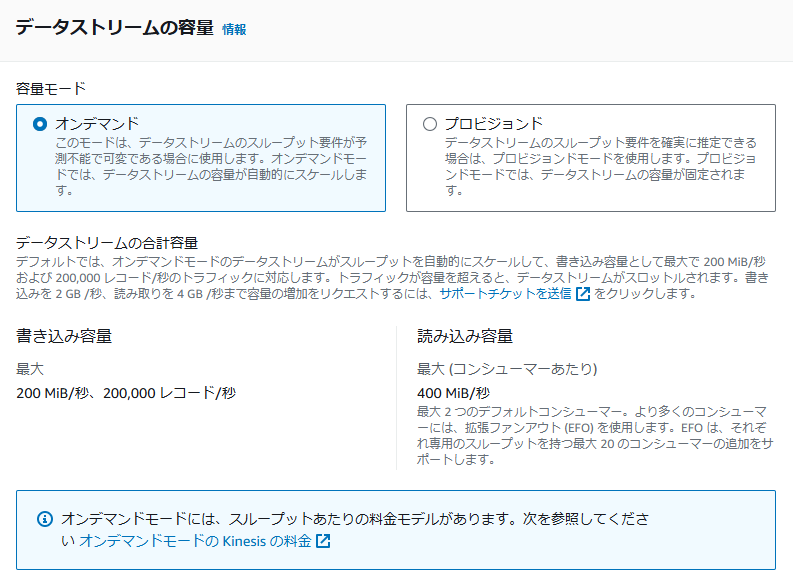
①-1 オンデマンドモード
容量計画が不要で、システムが自動的にスケーリングしてトラフィックに応じた処理を行います。
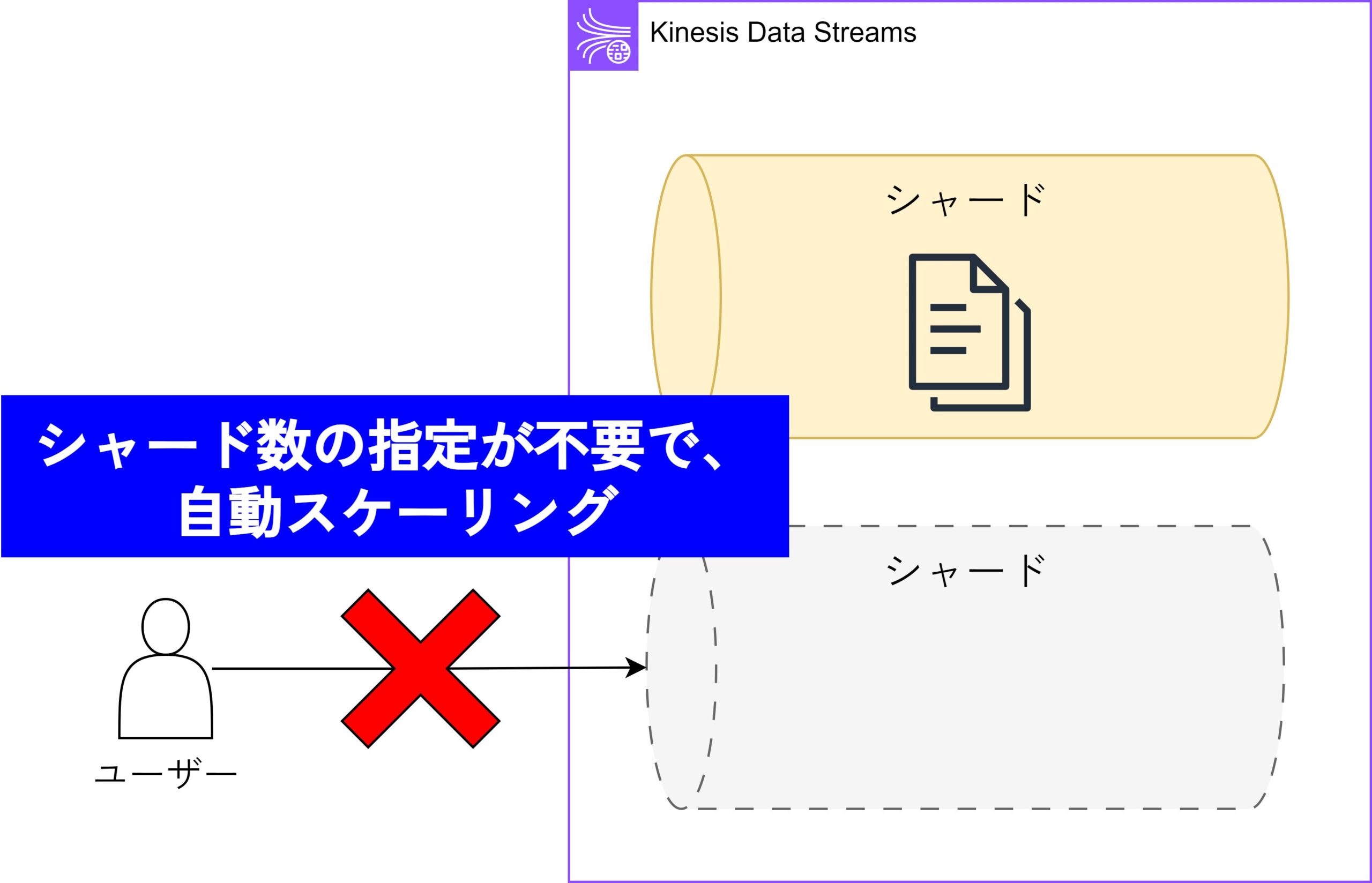
- 容量計画が不要で、手間がかからない。
- トラフィックの変動に自動的に対応できるため、過負荷の心配が少ない。
- 予測できない使用量に対してコストが高くなる可能性がある。
- 特定のパフォーマンス要件に合わせた細かな調整が難しい。
このモードでは、Kinesis Data Streamsがシャードを自動的に管理し、必要なスループットを提供するため、スケーラビリティに優れています。
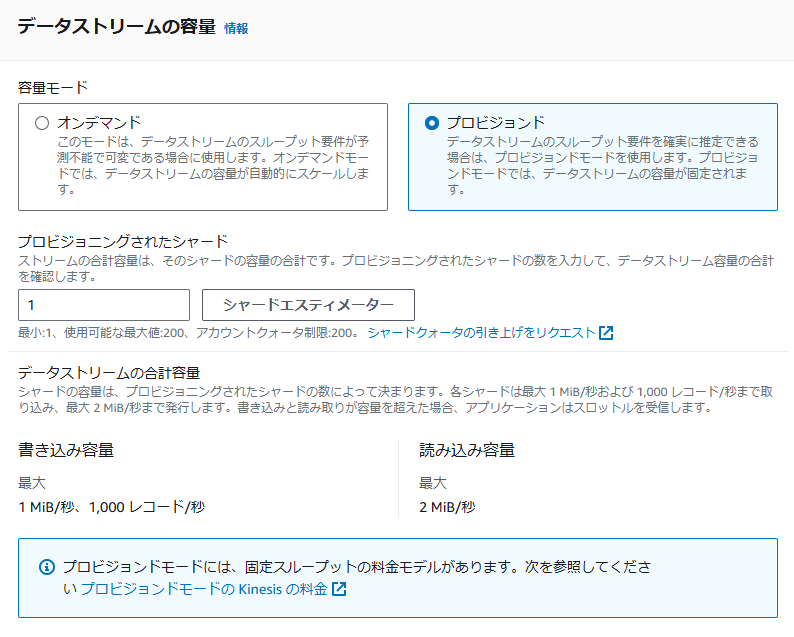
①-2 プロビジョニングモード
ユーザーがデータストリームのシャード数を指定し、その合計によってストリームの総容量が決まります。必要に応じてシャードの数を増減できるため、トラフィックの変動に合わせた柔軟な管理が可能です。
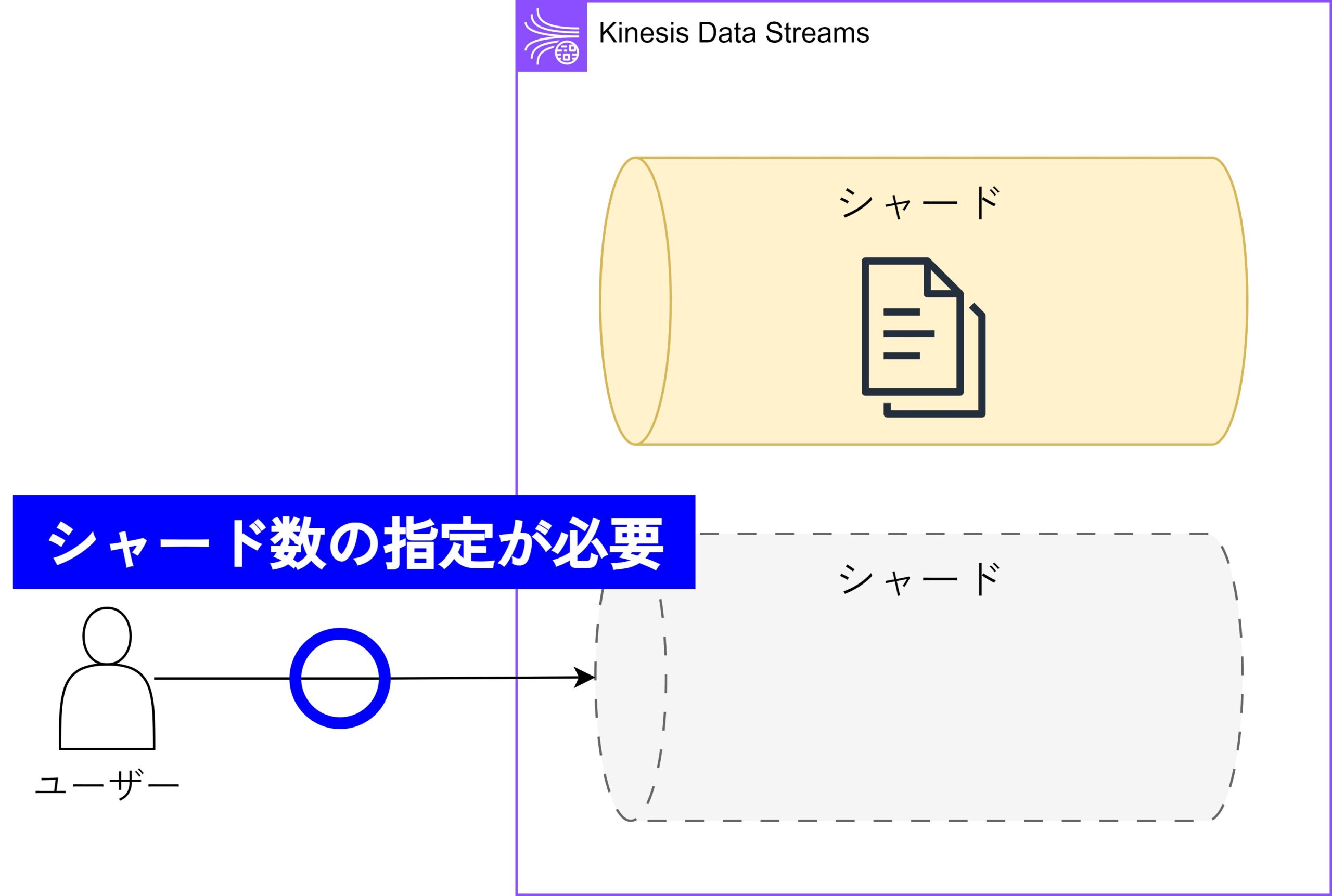
- トラフィックのニーズに応じてシャードを調整でき、コスト管理がしやすい。
- 特定のパフォーマンス要件に合わせた細かな設定が可能。
- 容量計画が必要で、事前に適切なシャード数を決める手間がかかる。
- シャードの管理に失敗すると、パフォーマンスの低下やデータロスのリスクが生じる。
また「プロビジョンドモード」を選択した場合には、以下項目を設定する必要があります。
- プロビジョニングされたシャード
- ユーザーがストリームのシャード数を手動で設定します。この数が多いほど、同時に処理できるデータの量が増加します。
- シャードの最小数は1、最大数は200です。
- シャードは1秒あたり最大1MBのデータを受信し、最大2つのトランザクションを処理可能です。これにより、シャード数を増やすことで、ストリーム全体の処理能力を柔軟に拡張できます。
②データ保持期間
デフォルトでは1日、最大で365日間データを保持できます。
③サーバー側の暗号化
指定したAWS KMSカスタマーマスターキーを使用してデータを自動的に暗号化し、保管中のデータのセキュリティを強化します。
この機能により、プロデューサーやコンシューマーは暗号化オペレーションを管理する必要がなく、データはKinesisサービスに出入りする際に自動的に暗号化されます。
④拡張メトリクスのモニタリング
Kinesis Data Streamsのメトリクスには以下の2種類があり、本項目では後者のメトリクスを取得するか否かを設定できます。
- デフォルトで取得されるメトリクス
- 拡張機能で取得できるメトリクス ※追加料金が発生
例えば、本項目を有効化することでIncomingRecordsやIncomingBytesといったメトリクスを取得できるようになります。
⑤データストリーム共有ポリシー
他のAWSアカウントとデータストリームを共有するためのアクセス制御を設定する機能です。
このポリシーにより、特定のAWSアカウントに対してストリームの読み取りや書き込みの権限を付与できます。これにより、複数のアカウント間でデータの共有が簡単に行えるようになります。
参考記事
本記事の解説は以上です。
ここからは、より知識を深めたい人向けに関連記事を紹介します。
類似サービス(Data Firehose)
Kinesis Data Streamsの類似サービスとして、「Data Firehose」が挙げられます。
このAWSサービスは、Kinesis Data Streasmと同様にストリームデータを扱うサービスになるので、以下の記事で違いや特徴を抑えることをおすすめします。
コメント