はじめに
Amazon EC2(Elastic Compute Cloud)は、AWSが提供する代表的なクラウドコンピューティングサービスです。
EC2を利用する際、適切なインスタンスタイプを選択することが非常に重要です。本記事では、EC2のインスタンスタイプの特徴と、用途に応じた選び方について詳しく解説します。
- インスタンスタイプの構成要素
- インスタンタイプの種類と選び方
EC2インスタンスタイプとは?
EC2インスタンスタイプとは、仮想サーバーの性能や特性を定義したものです。各タイプは、CPUの性能、メモリ容量、ストレージ、ネットワーキング能力などの組み合わせによって特徴づけられています。
例えばEC2を作成する際、インスタンスタイプは「c5a.large」のように表現されており、その中から用途に応じたタイプを選択する必要があります。
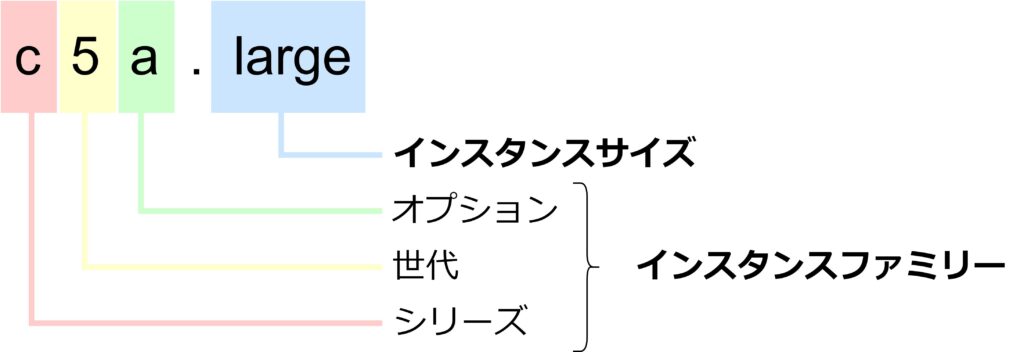
上記のイラストの通り、インスタンスタイプは以下4つの要素で構成されています。
以降では各構成要素を解説します。
- シリーズ
- 世代
- オプション
- インスタンスサイズ
①シリーズ
EC2インスタンスタイプにおける「シリーズ」とは、「m5.large」の「m」のように、インスタンスファミリーを表すアルファベットのことを指します。
各シリーズは特定の用途や性能特性に最適化されており、例えば「m」は汎用、「c」はコンピューティング最適化、「r」はメモリ最適化を表します。シリーズの選択は、アプリケーションの要件に基づいて行われ、適切なシリーズを選ぶことでワークロードに最適な性能とコスト効率を実現できます。
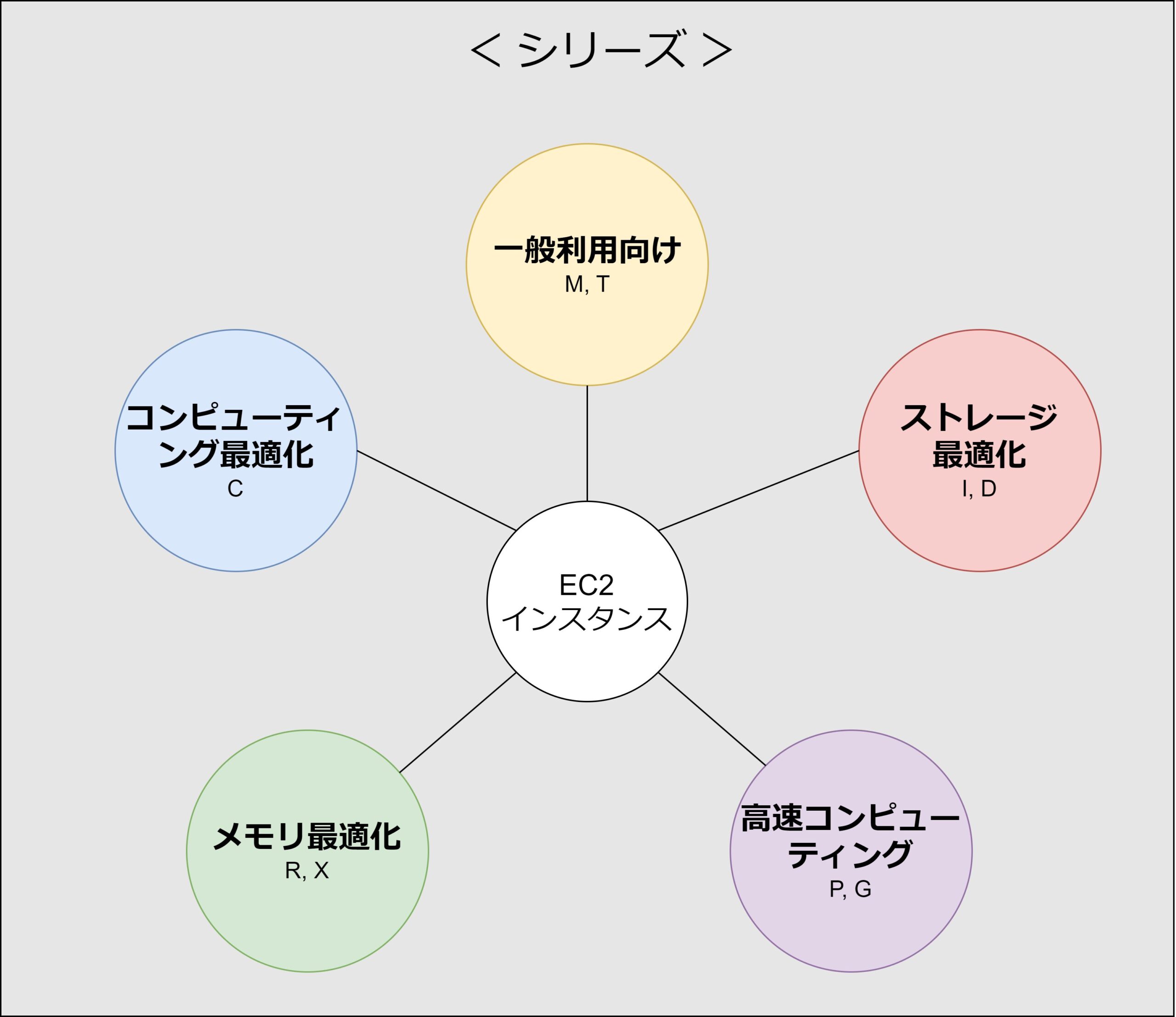
また上記のイラストの通り、「シリーズ」は用途に応じて以下の5種類に分類されます。
- 一般利用向け(M, T 等)
- コンピューティング最適化(C 等)
- メモリ最適化(R, X 等)
- 高速コンピューティング(P, G 等)
- ストレージ最適化(I, D 等)
一般利用向け
バランスの取れたコンピューティング、メモリ、ネットワークのリソースを提供し、多様なワークロードに使用できます。
- 中小規模なウェブアプリケーション
- 開発・テスト環境
M:汎用
バランスの取れたCPUとメモリを提供し、さまざまなアプリケーションやワークロードに適応できる柔軟性を持っています。
- 一般的な用途に対してコストパフォーマンスが良く、予算を抑えながら利用可能。
- 汎用的な性能を持つため、特定の最適化を行わなくても、多くのアプリケーションでスムーズに動作する。
- 特定の用途(例:高性能計算や大規模データ処理)には最適化されていないため、他の専門インスタンスに比べると性能が劣る場合がある。
- 一部の汎用インスタンスはバースト性能を提供しますが、持続的な高負荷には向かないことがある。
T:バースト可能
通常は低~中程度のCPU使用率で動作し、必要に応じて高いCPUパフォーマンスにバーストできる柔軟性を持つインスタンスタイプです。
- 基本的なコストが低く、必要なときにだけ性能をバーストさせることができる
- 一時的なトラフィックの増加やピーク時に対応するため、リソースの調整が容易
- バースト性能が持続できないため、長時間の高負荷には対応できない
- バーストのクレジットがなくなると、性能が基本レベルに戻るため、計画的な使用が必要
コンピューティング最適化
高いCPU性能を提供し、計算集約型のアプリケーションやワークロードに最適化されています。
- データ分析
- 大量のデータ処理やバッチ処理を行うデータ分析タスク。
- ゲームサーバー
- リアルタイムで処理を必要とするオンラインゲームのサーバー。
C:コンピューティング最適化
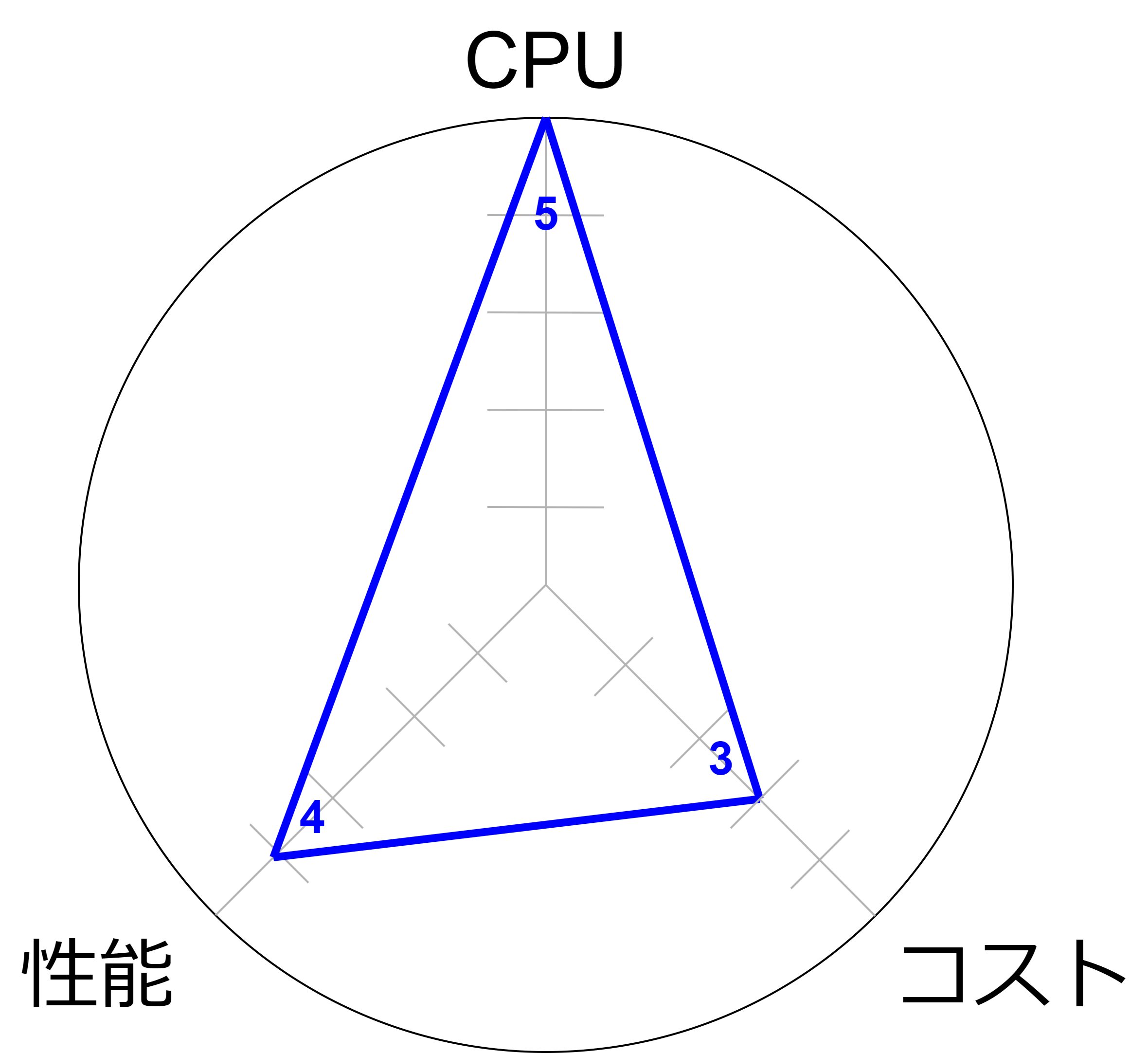
- 計算集約型のアプリケーションに対して優れた処理能力を提供し、パフォーマンスを向上させます。
- 一般的な汎用インスタンスに比べ、コストが高くなることが多い。
- 計算集約型のワークロードに特化しているため、メモリ集約型やストレージ集約型の用途には向いていない。
メモリ最適化
メモリ内の大きいデータセットを処理するワークロードに対して高速なパフォーマンスを実現するように設計されています。
- データベースサーバー
- 大規模なデータベースやトランザクション処理システム。
- ビッグデータ処理
- Apache SparkやHadoopなどのフレームワークを使用した大規模データ処理。
R:メモリ最適化
大量のメモリを提供し、メモリ集約型のアプリケーションやデータベースに最適化されているため、迅速なデータアクセスを実現します。
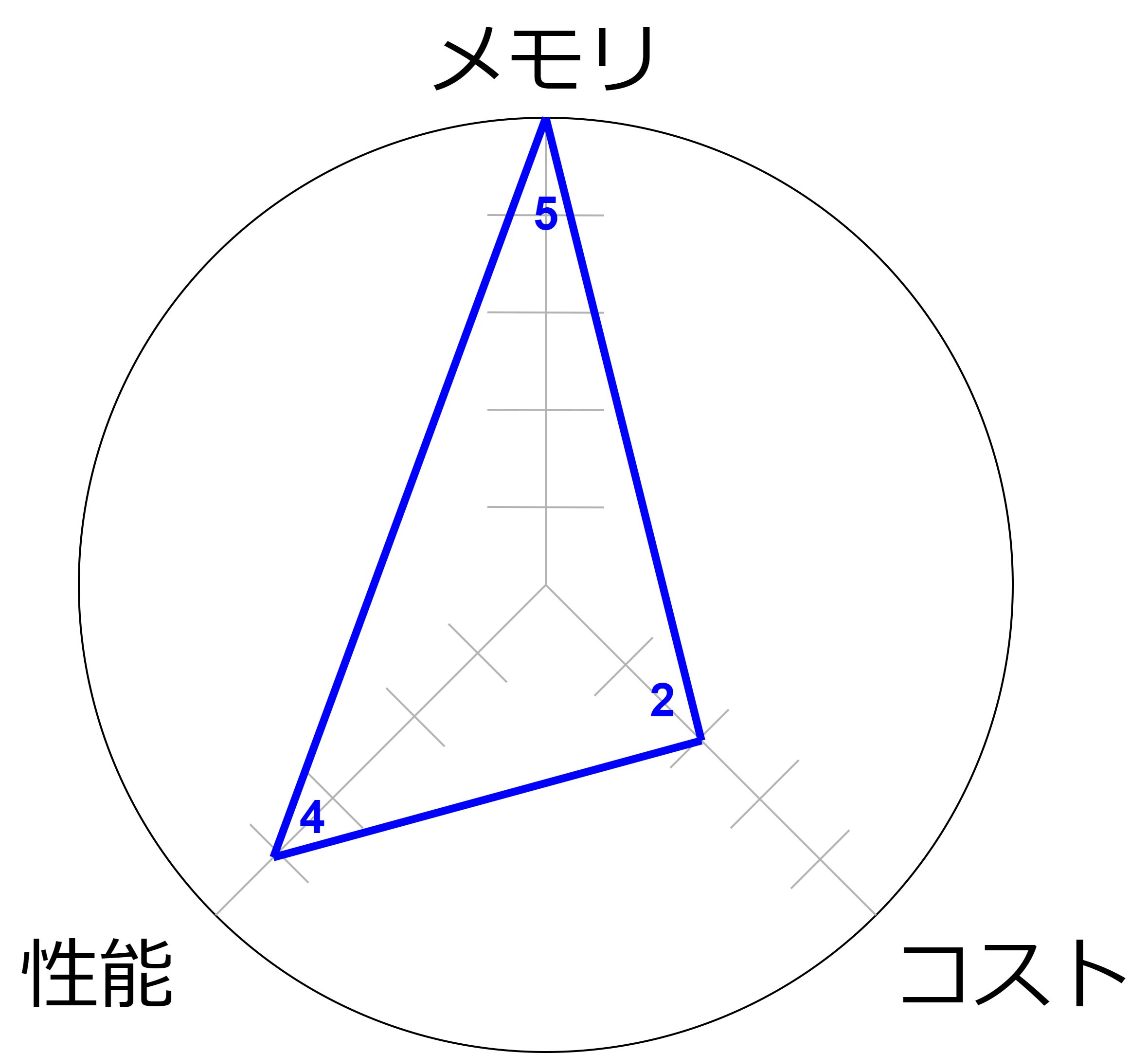
- メモリにデータを保持することで、ディスクI/Oの遅延を減らし、迅速なデータアクセスを実現します。
- 大規模なデータセットを扱う際に、計算処理が高速化され、全体のパフォーマンスが向上します。
- 大量のメモリを搭載しているため、コストが他のインスタンスに比べて高くなることが多い。
- メモリ集約型のアプリケーションに特化しているため、CPUやストレージに最適化されたワークロードには向いていない。
X:メモリ集約型
メモリ最適化(R)インスタンスよりもさらに大容量のメモリを提供し、特に非常に大規模なデータベースや高度なインメモリ処理に最適化されているため、データアクセスの高速化と計算処理のパフォーマンスを一層向上させることができます。
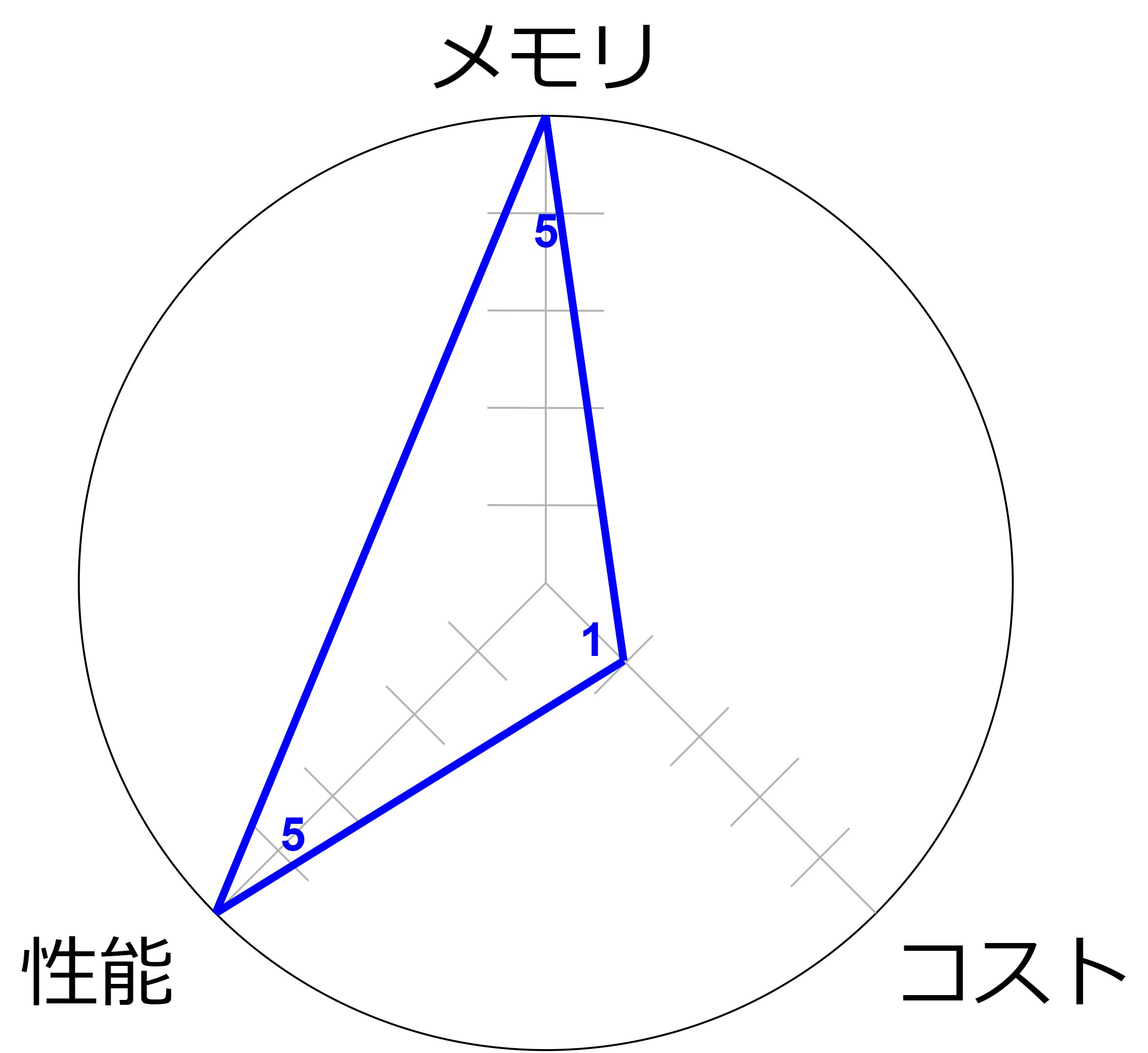
- 極めて大規模なデータセットを扱うために設計されており、膨大な量のデータをメモリに保持できます。
- 高度なインメモリアプリケーションやデータベースにおいて、処理速度が向上し、全体的なパフォーマンスが改善されます。
- 大量のメモリを搭載しているため、コストが非常に高くなることが多いです。
- メモリ集約型のアプリケーションに特化しているため、一般的な用途や他のワークロードには向いていない。
高速コンピューティング
ハードウェアアクセラレーター (コプロセッサ) を使用して、浮動小数点計算、グラフィックス処理、データパターン照合などの機能を、CPU で実行中のソフトウェアよりも効率的に実行します。
- 大規模データ分析
- 膨大なデータセットから有意義な情報を抽出するための解析。
- シミュレーション
- 複雑なシステムや現象の動作を模擬し、結果を予測するための計算。
P:GPU高速化
高度な並列処理能力を活かして、機械学習やディープラーニング、科学計算などの計算集約型アプリケーションの性能を大幅に向上させるために最適化されています。
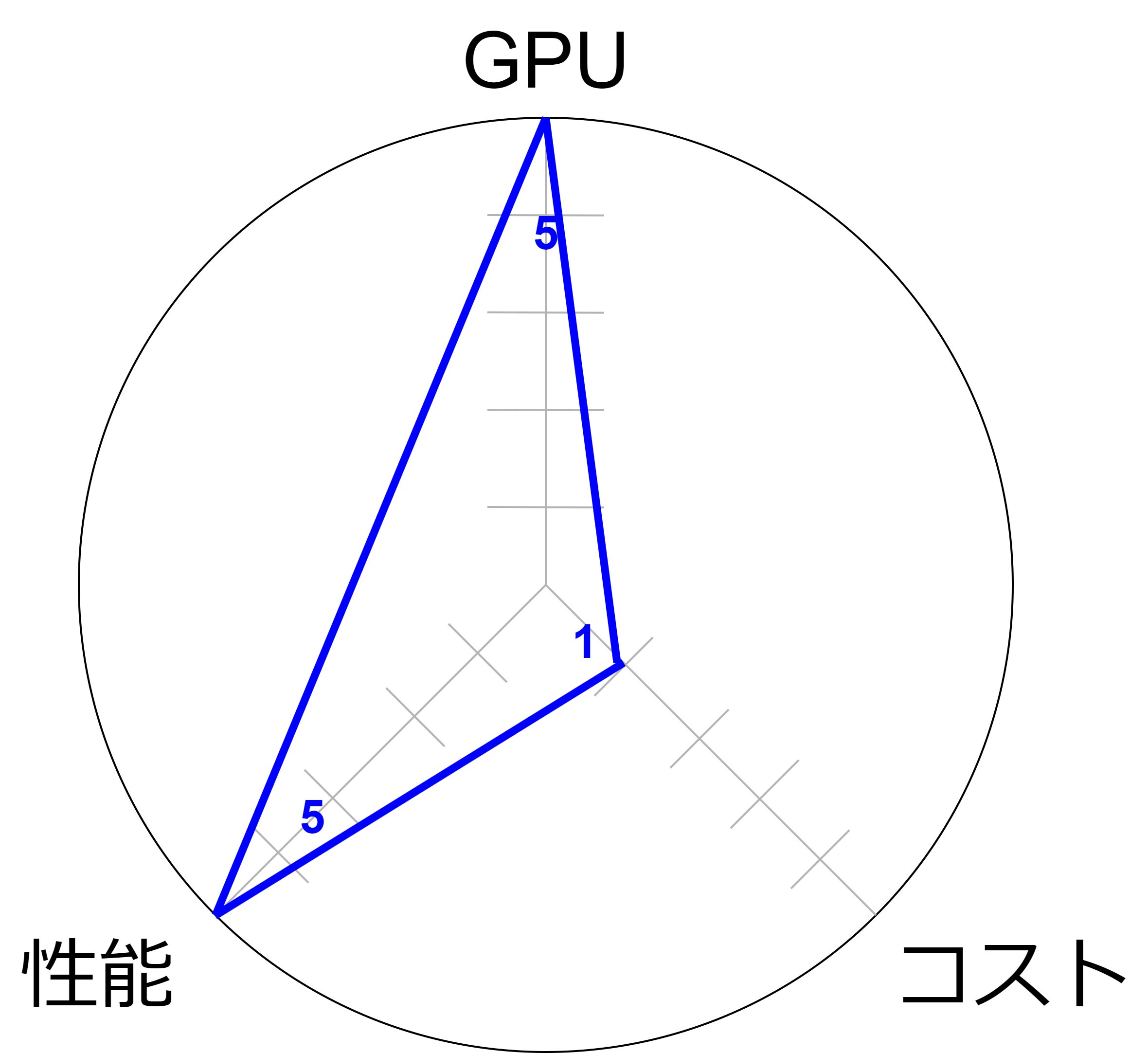
- 多数のコアを持ち、大量のデータを同時に処理できるため、特に機械学習や科学計算でのパフォーマンスが向上します。
- 複雑な計算やアルゴリズムの実行において、CPUに比べて高い性能を発揮します。
- GPUリソースは高価なため、長時間の利用や高負荷作業ではコストがかさむことがあります。
- GPUは特定の計算タスクに最適化されているため、一般的な計算やI/O処理には向かない場合があります。
G:グラフィック最適化
高度なグラフィックス処理能力を提供し、ゲーム開発やビジュアライゼーション、機械学習などのアプリケーションにおいて、リアルタイムで高品質な映像を生成するために特化しています。
ストレージ最適化
ローカルストレージの大規模データセットに対する高いシーケンシャル読み取りおよび書き込みアクセスを必要とするワークロード用に設計されています。
- データウェアハウス
- 大規模なデータセットを集約・分析するためのデータウェアハウスの構築。
- ストリーミングデータ処理
- リアルタイムでデータを取り込み、処理・保存するためのアプリケーション。
I:ストレージ最適化
高いI/O性能を提供し、データベースやトランザクション処理に最適化されているため、高速なデータアクセスと処理を実現します。
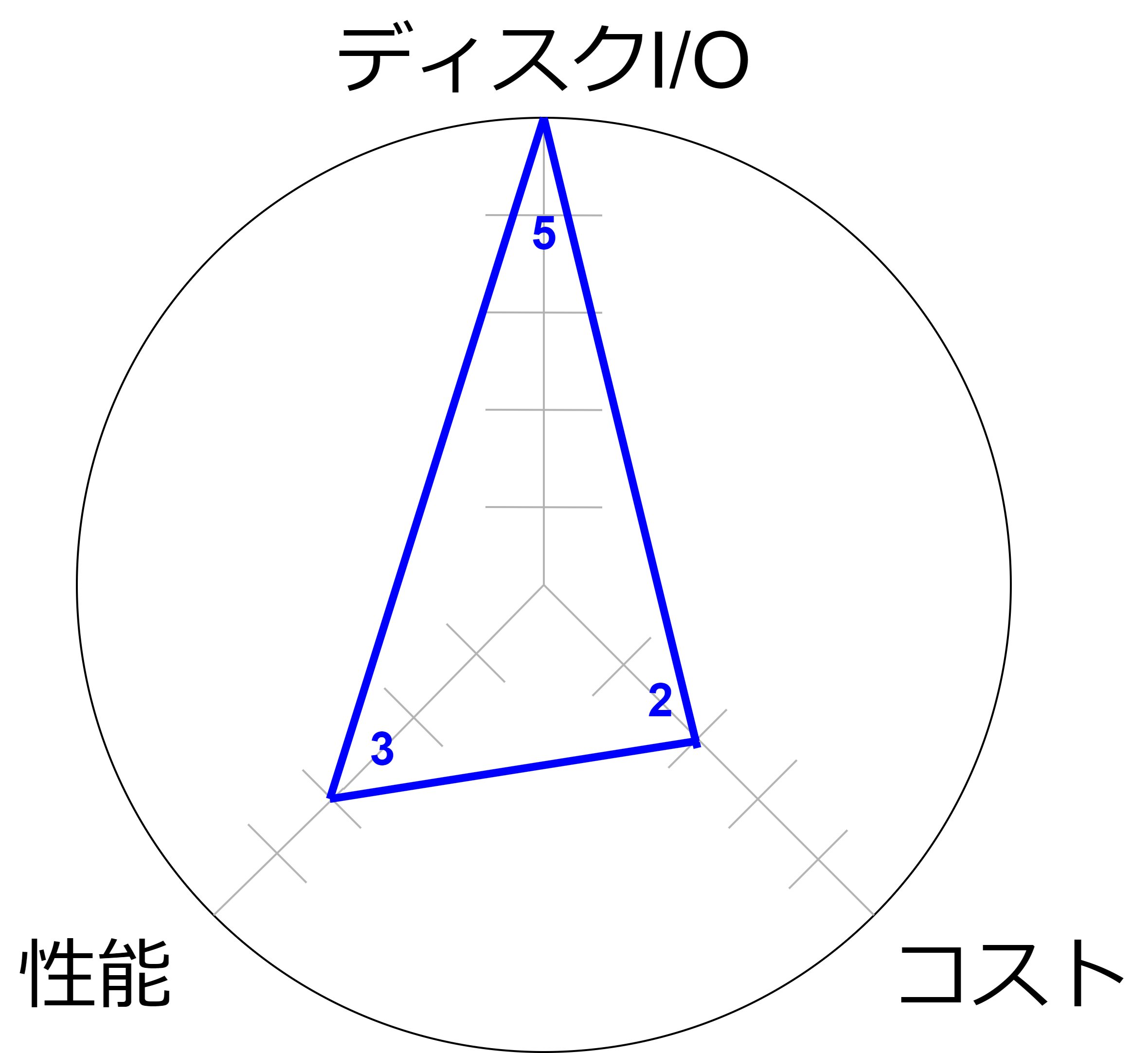
- 高速なデータ読み書きが可能で、データベースやリアルタイム処理において優れたパフォーマンスを提供します。
- データアクセスの遅延が少なく、迅速な応答が求められるアプリケーションに最適です。
- 高性能なストレージは一般的にコストが高くなるため、長期的な運用コストが増加する可能性があります。
- 高いI/O性能を必要としないアプリケーションには過剰なリソースとなることがあります。
D:高密度ストレージ
大容量のデータをコスト効率良く保存するために最適化されており、大規模なデータセットやアーカイブデータの管理に適しています。
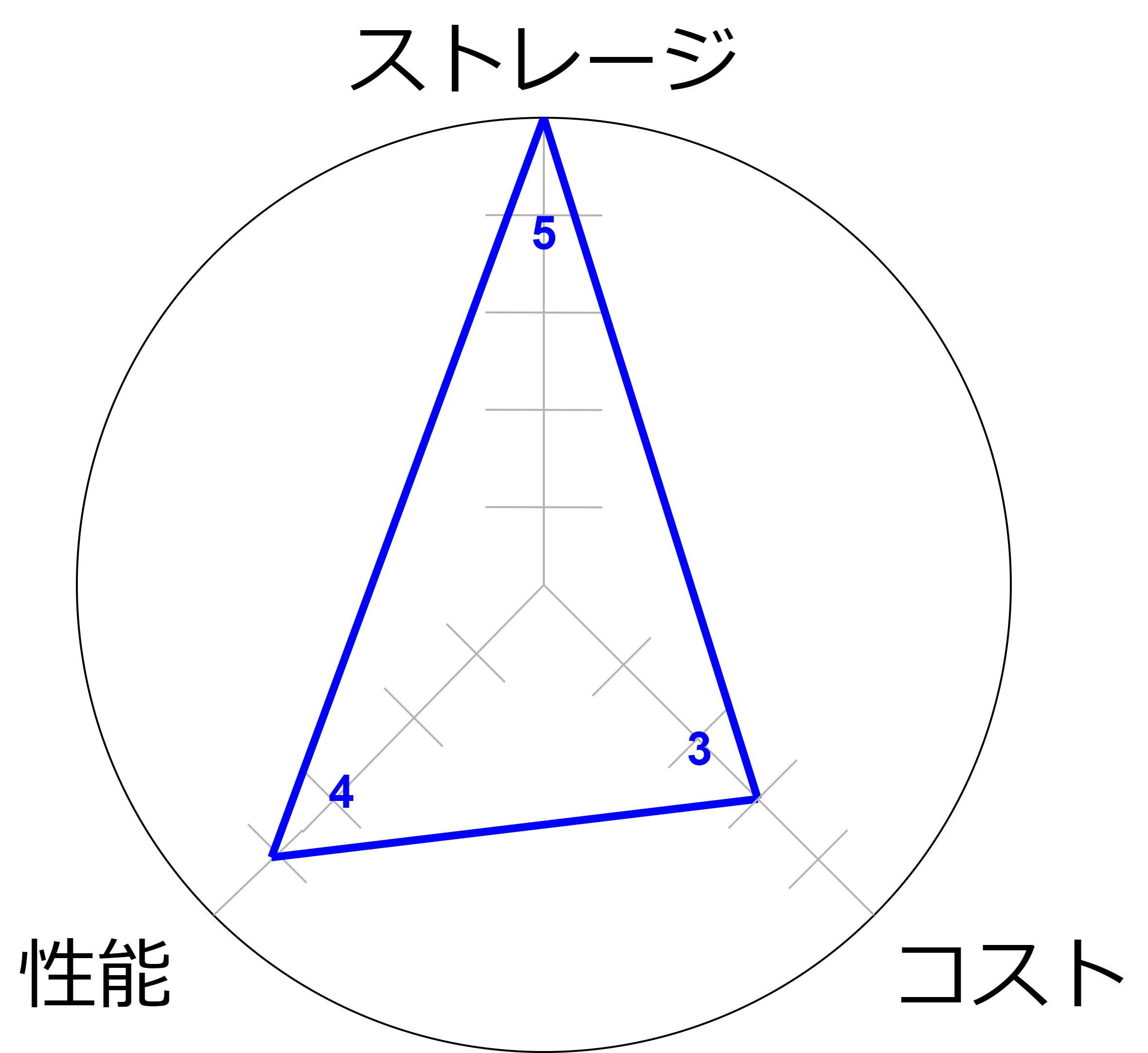
- 大容量のデータを安価に保存できるため、長期的なデータ保存に適しています。
- 非常に大きなデータセットを管理できるため、アーカイブやバックアップに理想的です。
- 高密度ストレージは一般的にI/O性能が低いため、リアルタイムデータ処理には向いていないことがあります。
- データアクセスが遅くなる可能性があり、迅速な応答が求められるアプリケーションには不向きです。
②世代
EC2インスタンスのアーキテクチャや性能の進化を示しています。
各世代(第1世代から第5世代まで)は、CPUやメモリの性能向上や新しい技術の導入により、より高い効率と特化した機能を提供しています。最新の世代を選ぶことで、コスト効率と性能を最大化できます。
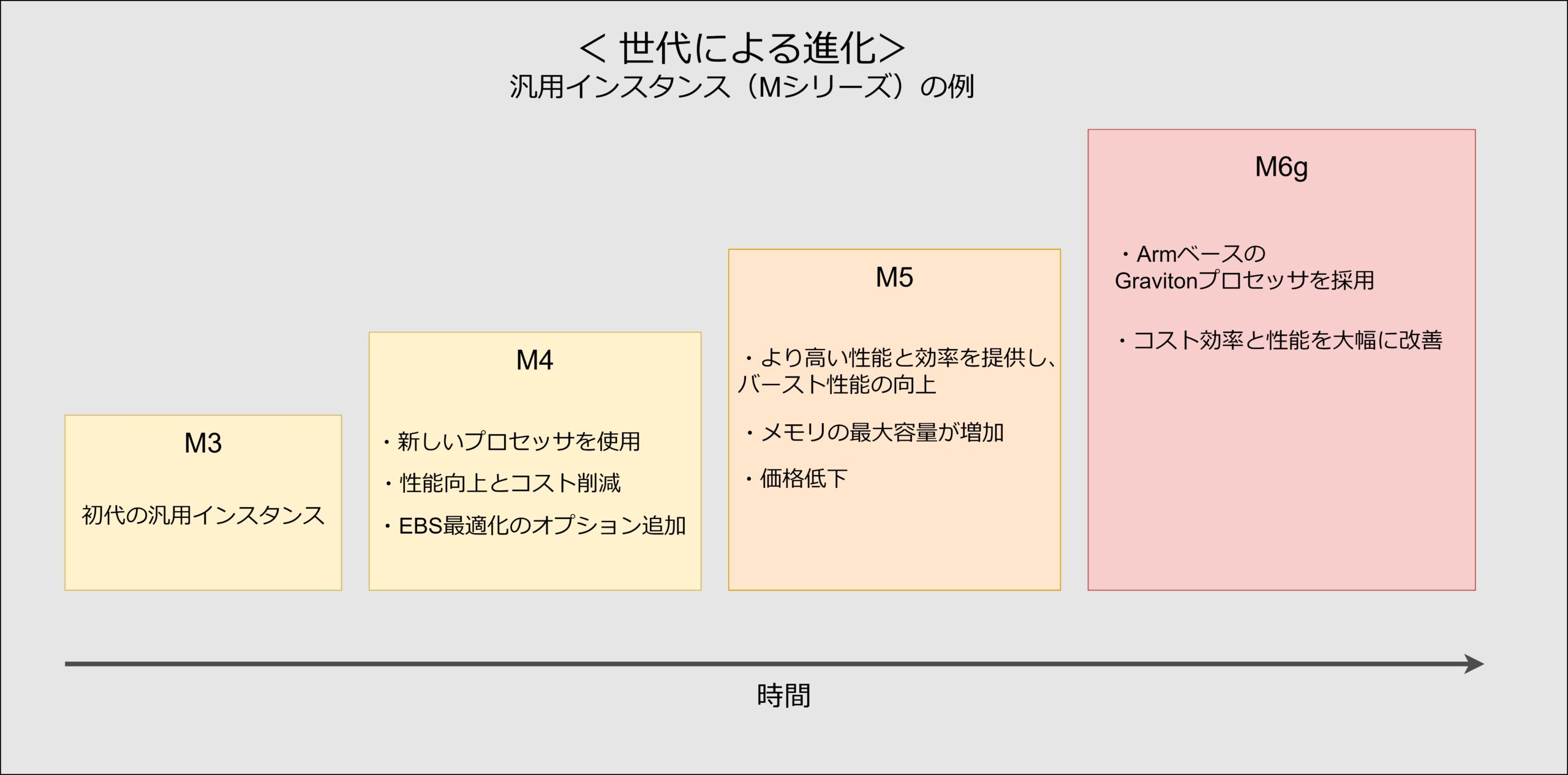
③オプション
インスタンスタイプにおける「オプション」には、特定のハードウェアアーキテクチャや機能を示す文字が付加されます。
例えば、「a」はArmアーキテクチャを使用したインスタンスで、コスト効率が高いのが特徴です。また、「g」はグラフィックス処理能力を強化したインスタンスを示し、GPUを搭載しているため、機械学習や3Dレンダリングなどのグラフィックス集約型アプリケーションに適しています。
<代表的なオプション>
| オプション | 説明 | 例(インスタンスタイプ) |
|---|---|---|
| a | AMD プロセッサを使用したインスタンス | t3a |
| g | AWS Graviton プロセッサを使用したインスタンス | t4g |
| d | ローカルNVMeベースのSSDストレージを備えたインスタンス | m6gd |
| n | 高ネットワークパフォーマンスを提供するインスタンス | r5n |
④インスタンスサイズ
インスタンスサイズは、各インスタンスタイプのリソース(vCPU、メモリ、ネットワーク性能など)の量を示します。
サイズは通常、小規模から大規模なニーズに対応するために、nano、micro、medium、small、large、xlarge といった複数のオプションがあり、選択したサイズによってインスタンスのパフォーマンスやコストが変わります。適切なサイズを選ぶことで、コスト効率と必要な性能を両立できます。
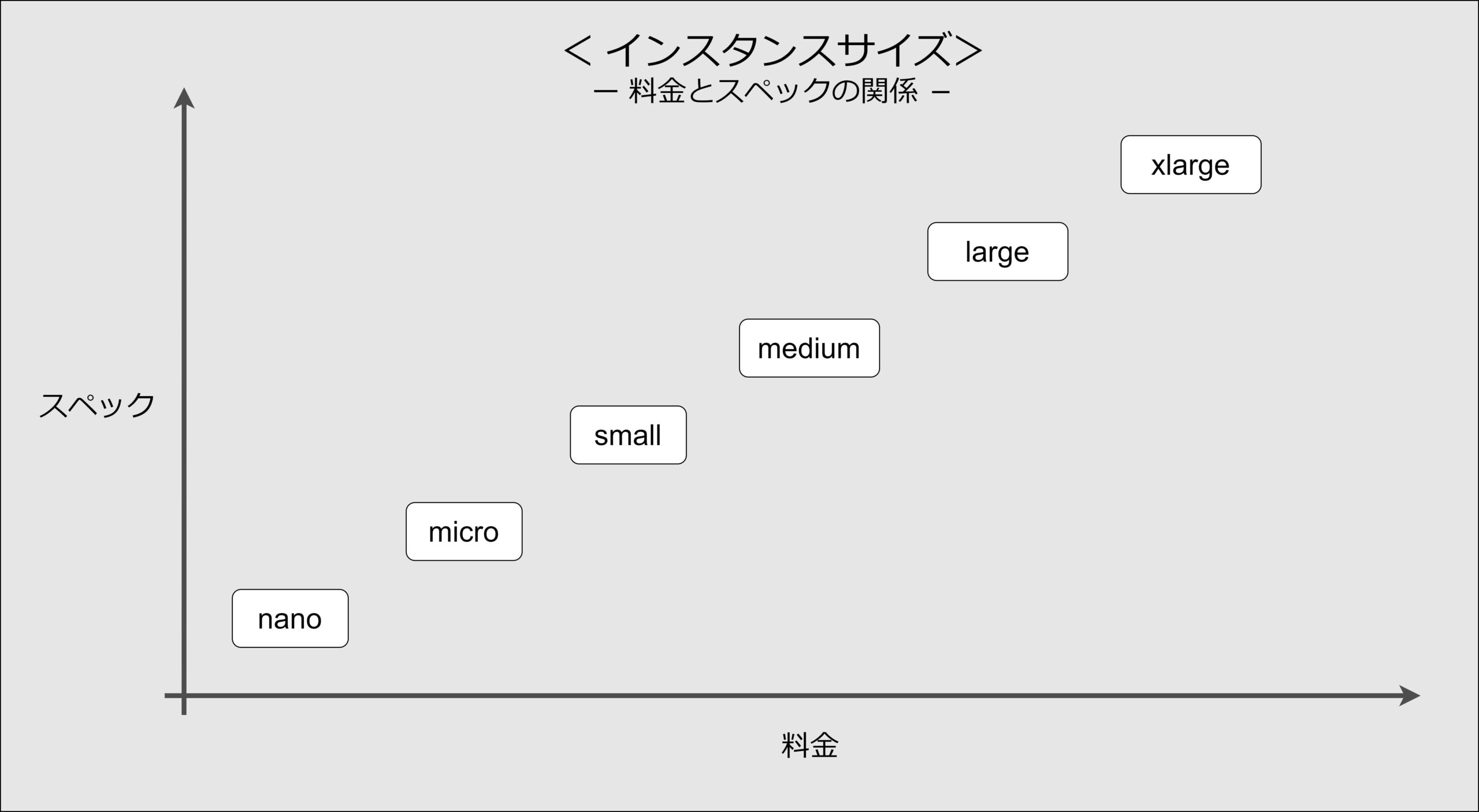
- 種類
-
- nano:最小モデル
- micro:小規模モデル
- small : エントリーモデル
- medium : 標準モデル
- large : ハイスペックモデル
- xlarge : 最上位モデル
- サイズによる違い:
-
- CPU(処理能力)
- 大きいサイズほど、CPUのコア数や処理速度が高くなります。
- メモリ(RAM)
- 大きいサイズほど、搭載されるメモリ量が増えます。
- ストレージ
- 大きいサイズほど、利用可能なストレージ容量も増えることがあります。
- ネットワーク性能
- 大きいサイズほど、データ転送速度が向上することがあります。
- CPU(処理能力)
関連記事
本記事の解説は以上です。
ここからは、より知識を深めたい人向けに関連記事を紹介します。
本記事で登場したAWSサービス
本記事では、「EC2」のインスタンスタイプに焦点を当てて解説しましたが、EC2について包含的に理解を深めたい方は以下の記事をご覧ください。
概要や構成要素を図解しているので、初心者でも理解しやすい内容になっています。

コメント