
本記事の内容
本記事では、初めてData Firehoseを扱う人やAWS認定資格取得を目指す方向けに、Data Firehoseの基礎知識を解説します。
- Data Firehoseの仕組み
- Kinesis Data Streamsとの違い
- 作成時の設定項目
Data Firehoseの概要

リアルタイムで大量のデータを収集、ストレージ、分析するためのフルマネージドサービスです。
様々なデータソースから生成されるストリーミングデータを、Amazon S3やAmazon Redshiftなどのストレージや分析サービスにシームレスに転送し、データ分析や機械学習の基盤として活用できます。
【サービス名の変更について】
元々は「Amazon Kinesis Data Firehose」という名前でしたが、2024年2月9日から「Amazon Data Firehose」という名前に変更されました。
Data Firehoseの仕組み
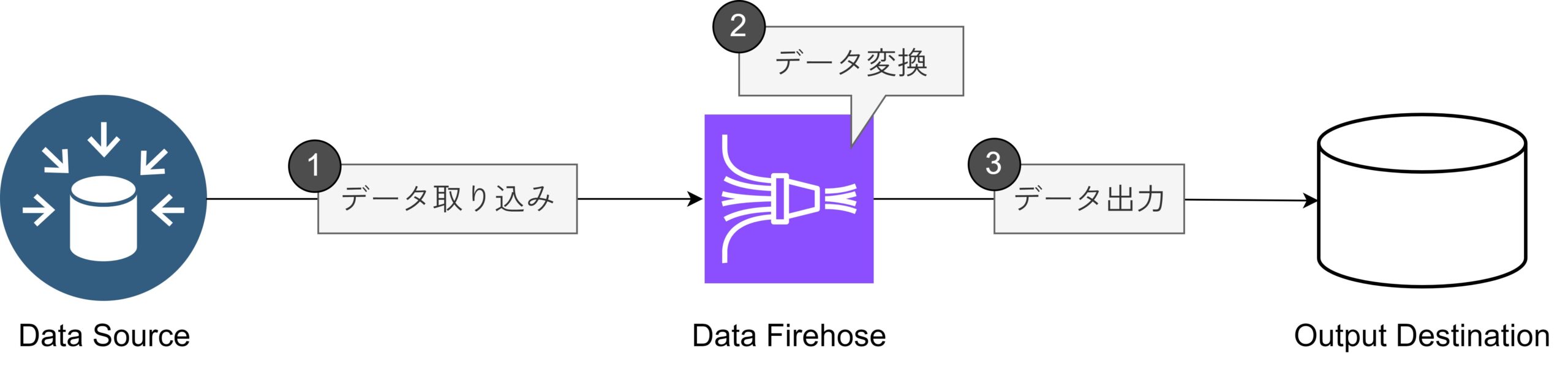
さまざまなデータソースから、大量のリアルタイムデータを取り込むことができます。
取り込まれたデータは、カスタムの変換ロジックを使って加工・整形されます。例えば、特定のフィールドを抽出したり、データ形式を変換したりするなどの処理が可能です。
これによって、分析や出力に適した形式にデータが変換されます。
処理されたデータは、最終的に他のシステム(データベース、分析ツール、ダッシュボードなど)に配信されます。これにより、リアルタイムでのデータ分析や可視化が可能になります。
Data Firehoseの特徴
以降では、Data Firehoseの以下特徴について解説します。
- 自動バッチ処理
- シームレスなデータ変換
- 簡単な設定と運用
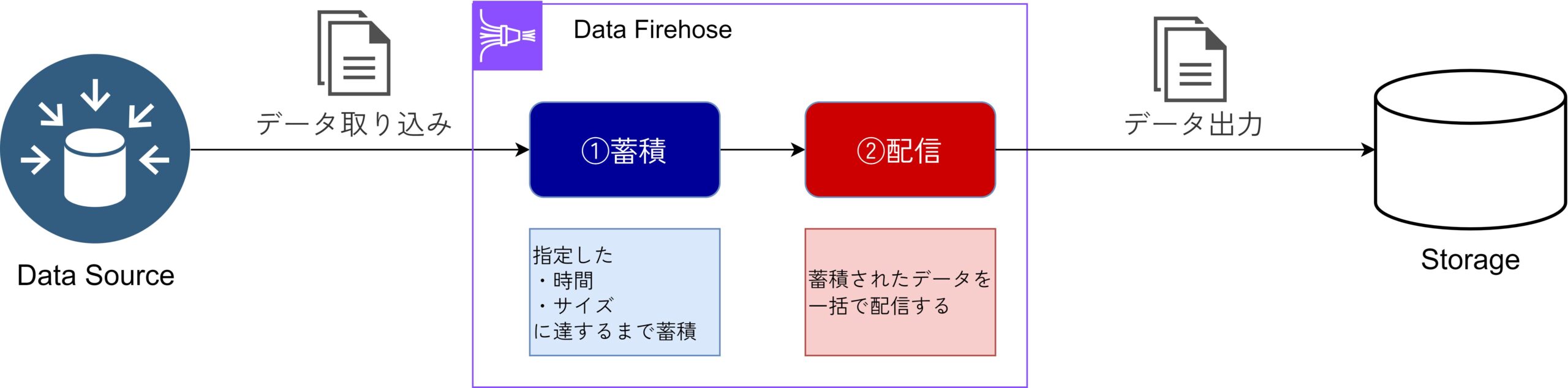
特徴①:自動バッチ処理
Data Firehoseでは、データを指定した時間またはサイズに達するまで蓄積し、一括で変換・ストレージへ配信できます。
このプロセスにより、ネットワーク効率が向上し、データ転送コストが抑えられるため、ユーザーは手間をかけずにリアルタイムデータを管理できます。設定も柔軟で、具体的なビジネスニーズに応じて調整が可能です。
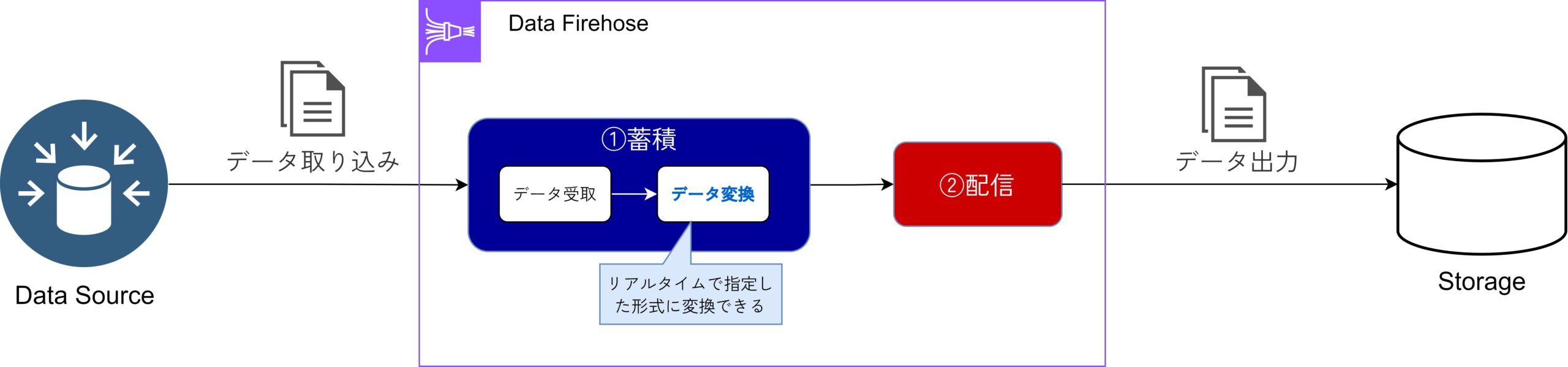
特徴②:シームレスな変換
受信したデータをリアルタイムで指定された形式に自動的に変換することが可能です。
この変換により、ユーザーは手動でデータを整形する必要がなく、必要な形式でデータをストレージに送信できます。例えば、JSONデータをCSVに変換することで、後続の分析や処理が容易になります。
特徴③:簡単な設定と運用
Data Firehoseは、直感的なユーザーインターフェースを提供しており、特別なプログラミングスキルがなくても簡単に設定できます。この使いやすさにより、迅速にデータパイプラインを構築し、運用を開始できるため、ビジネスニーズに素早く対応可能です。
また、設定後は自動的にデータを処理・配信するため、メンテナンスの手間も最小限に抑えられます。
Kinesis Data Streamsとの違い
「Data Firehose」と「Kinesis Data Streams」はどちらもリアルタイムデータの取り込み・変換・配信を行いますが、以下のような違いがあります。
- Data Firehose
- データをバッチ処理して簡単にストレージに配信する
- Kinesis Data Streams
- リアルタイムでデータをストリーミングし、柔軟なカスタマイズや低遅延の処理が可能。
<比較表>
| 比較項目 | Data Firehose | Kinesis Data Streams |
|---|---|---|
| 目的 | ストリームデータを出力先に配信する | ストリームデータをリアルタイム処理できるように保持する |
| データ処理形式 | バッチ処理 | リアルタイム処理 |
| データの処理間隔 | 秒単位 ※設定可能 | 1秒未満 |
| データ変換処理の柔軟性 | 限定的 (Data Firehoseの設定ベースで変換処理が可能) | 高い (コンシューマーによるによる変換処理が可能) |
| 利用シーン | ログ送信 | リアルタイム分析 |

「Kinesis Data Streams」については、以下の記事で詳しく図解しているので、ぜひご確認ください。

Data Firehoseの設定項目
ここからは、Data Firehoseを作成する際の設定項目を解説します。
【設定項目】
①ソースと送信先
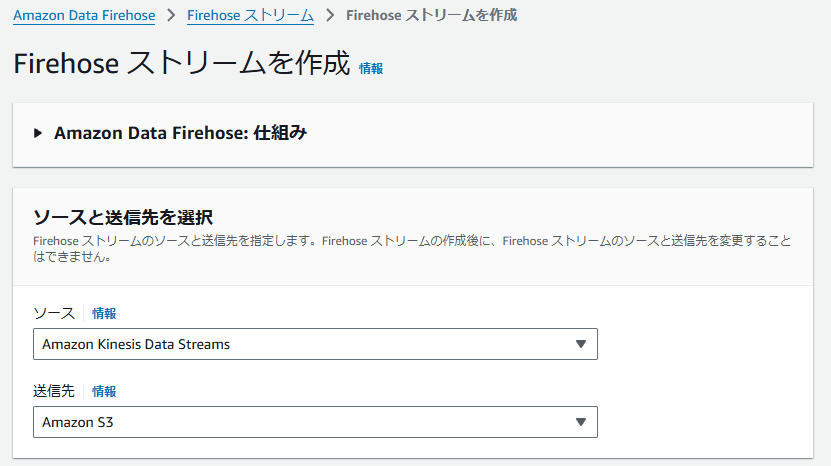
①-1 ソース
データの入力元を指定する項目です。この設定により、収集するデータのタイプや流れを定義し、リアルタイムでのデータ処理を開始することができます。
- Amazon Kinesis Data Streams
- リアルタイムでストリーミングデータを処理するためのサービスで、複数のデータプロデューサーからデータを取り込むことができます。
- Amazon MSK
- Apache Kafkaをフルマネージドで提供するサービスで、データのストリーミングと集約を行うために利用されます。
- Direct PUT
- アプリケーションやサービスが直接Data Firehoseにデータを送信できるオプションで、HTTP POSTリクエストを通じて即座にデータを取り込むことができます。
①-2 送信先
収集したデータをどこに送信するかを指定する重要な項目です。
選択肢には、Amazon S3、Amazon Redshift、Snowflake、さらにはHTTPエンドポイントなどがあり、用途に応じて適切なストレージや分析サービスを選ぶことができます。この設定により、データの保存や分析が効率的に行えるようになります。
②ソースの設定
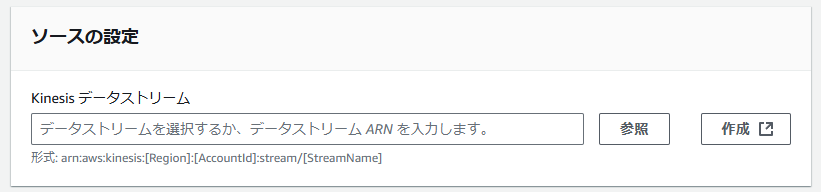
<ソースに「Amazon Kinesis Data Streams」を選択した場合>
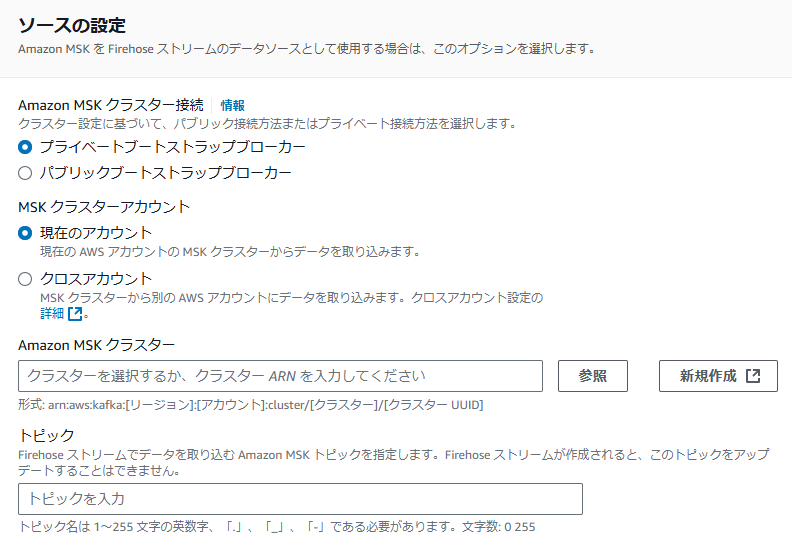
<ソースに「Amazon MSK」を選択した場合>
②-1 Kinesis データストリーム ※「Amazon Kinesis Data Streams」を選択した場合
データの入力元となる、Kinesis データストリームを選択します。
②-2 Amazon MSK クラスター接続 ※「Amazon MSK」を選択した場合
Amazon MSK クラスターへの接続方法を選択します。クラスターの設定に応じて、パブリックまたはプライベートの接続オプションを選択できるため、セキュリティやネットワークの要件に合わせた接続が可能です。
- プライベートブートストラップブローカー
- VPC内でのみアクセスできるプライベートIPアドレスを使用してクラスターに接続します。
- これにより、内部ネットワークからのセキュアな接続が実現され、インターネットに公開されないため、セキュリティが強化されます。
- パブリックブートストラップブローカー
- インターネット経由でアクセスできるパブリックIPアドレスを使用してクラスターに接続します。
- これにより、外部からもデータを容易に送信できる利便性が得られますが、セキュリティ上のリスクが高まるため、適切な認証やアクセス制御が必要です。
②-3 MSK クラスターアカウント ※「Amazon MSK」を選択した場合
データを取り込むMSKクラスターが存在するAWSアカウントを選択するための設定項目です。
②-4 Amazon MSK クラスター ※「Amazon MSK」を選択した場合
データを取り込むMSKクラスターのARNを設定します。
②-5 トピック ※「Amazon MSK」を選択した場合
Firehoseストリームでデータを取り込むためのAmazon MSKトピックを指定します。トピックは、データの分類や整理に用いられるKafkaの基本的な構成要素で、特定のデータストリームを識別します。
③レコードを変換および転換
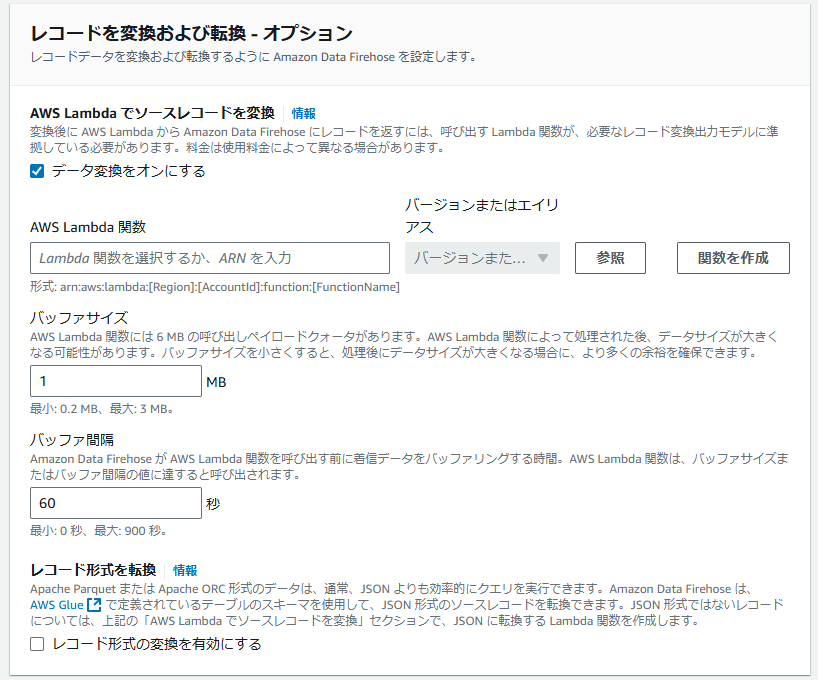
③-1 AWS Lambdaでソースレコードを変換
Data FirehoseがAWS Lambdaを利用して、取り込むソースレコードを変換する機能をオンにすることができます。指定されたLambda関数は、受信したデータを適切な形式に変換し、その結果をData Firehoseに返します。
③-2 AWS Lambda関数
レコード変換処理を行うLambda関数を選択します。
③-3 バッファサイズ
バッファサイズは、Lambda関数が処理するデータの量を制限するための設定です。
具体的には、バッファサイズを小さく設定すると、AWS Lambda関数が呼び出される際に、一度に処理されるデータ量が制限されます。これにより、Lambda関数が6 MBのペイロードクォータを超えないようにすることができます。
バッファサイズを小さく設定すると、処理後のデータが大きくなった場合でも余裕を持たせることができます。バッファサイズは最小0.2 MBから最大3 MBまで選べるため、状況に応じて適切なサイズを選ぶことが重要です。
③-4 バッファ間隔設定
Data FirehoseがLambda関数を呼び出す前に、受信したデータをどのくらいの時間ためるかを指定します。具体的には、設定した時間(バッファ間隔)が経過するか、バッファサイズが設定した容量に達すると、Lambda関数が呼び出されてデータが処理されます。
バッファ間隔は最小0秒から最大900秒(15分)まで設定可能です。短い間隔を選ぶと、データが早く処理されますが、頻繁に呼び出されるため、コストがかさむことがあります。一方、長い間隔を選ぶと、一度にまとめて処理されるため効率的ですが、データの処理に時間がかかることになります。適切なバッファ間隔を選ぶことで、データ処理のバランスを取ることができます。
③-5 レコード形式を転換
受信したデータを効率的にクエリできる形式に変換することができます。具体的には、Apache ParquetやApache ORCといった形式にデータを変換することで、JSON形式よりもクエリ処理が速くなります。
Data Firehoseは、Glueで定義されたテーブルのスキーマを使用して、JSON形式のデータをこれらの効率的な形式に変換します。また、JSON形式でないレコードは、別途 Lambdaを利用してJSON形式に変換する必要があります。この設定を有効にすると、データがより使いやすく、効率的に処理されるようになります。
④送信先の設定
選択した送信先によって設定項目が大きく異なるので、共通的なバッファ・圧縮・暗号化に関する設定項目を解説します。

④-1 バッファサイズ
Data Firehoseが着信したレコードをAmazon S3バケットに配信する前に、どのくらいのデータをためるかを指定します。設定したバッファサイズに達すると自動的にトリガーされ、データが一括でS3に送信されます。
バッファサイズが大きいほど、一度に多くのデータをまとめて送信できるため、コストが低くなりますが、データがS3に配信されるまでの時間(レイテンシー)が長くなる可能性があります。逆に、バッファサイズが小さいと、データの配信が速くなりますが、コストが高くなり、レイテンシーは短くなります。
設定できるバッファサイズは、最小1 MiBから最大128 MiBまでで、推奨値は5 MiBです。適切なバッファサイズを選ぶことで、コストとパフォーマンスのバランスを取ることができます。
④-2 バッファ間隔
Data Firehoseが受信したデータをS3バケットに送信する前に、どのくらいの時間データをためるかを指定します。間隔を長く設定すると、データが収集される時間が増えるため、より多くのデータが一度にまとめて送信される可能性があります。
一方で間隔を短く設定すると、データがより頻繁に送信されるため、リアルタイムに近い形でデータのアクティビティを確認できるメリットがあります。これにより、データの変化を迅速に捉えられるため、分析やモニタリングが効果的になります。
設定できるバッファ間隔は、最小0秒から最大900秒(15分)までで、推奨される値は300秒(5分)です。この設定を適切に調整することで、データの配信頻度と収集効率を最適化できます。
④-3 データレコードの圧縮
Data Firehoseは、S3バケットに配信する前にデータを圧縮することができます。
これにより、ストレージコストが削減され、データ転送の速度も向上します。圧縮形式としては、一般的にGZIPが使用されます。圧縮を有効にすることで、特に大量のデータを扱う場合に、効率的なデータ管理が可能になります。
④-4 データレコードの暗号化
Data FirehoseがS3バケットに配信するデータレコードをどのように暗号化するかを指定します。
- S3 バケットの暗号化設定を使用
- S3バケットのデフォルトの暗号化設定が適用されます。通常、これはAmazon S3によるサーバー側の暗号化(SSE-S3)で、デフォルトでデータを暗号化して保存します。
- この方式は、手軽にデータの暗号化を実現できるため、初心者にも扱いやすいです。
- SSE-KMS を使用
- KMSを使用したサーバー側の暗号化(SSE-KMS)が適用されます。この方法では、より細かい制御や管理が可能で、特定のKMSキーを指定して暗号化を行えます。
- これにより、アクセス管理や監査の要件を満たすことができ、より高いセキュリティを提供します。
⑤詳細設定

⑤-1 サーバー側の暗号化
Data Firehoseがデータを保存する際に使用する暗号化の方法を指定します。具体的にはKMSを活用して、暗号化に必要なキーを作成・管理し、AWSのさまざまなサービスで暗号化の使用を制御します。
このオプションを選択することで、Firehoseストリームに取り込まれるデータに対してサーバー側の暗号化(SSE)を適用することができます。これにより、データが不正にアクセスされるリスクを低減し、セキュリティを強化します。
⑤-2 Amazon CloudWatch エラーのログ記録
Data Firehoseがレコードの配信中に発生したエラーをAmazon CloudWatch Logsに記録するかどうかを指定します。CloudWatch Logsを使用することで、エラーの詳細をリアルタイムで監視・分析できるため、問題の迅速な特定と対応が可能になります。
⑤-3 サービスアクセス
Data Firehoseが正常に動作するために必要な権限を持つ、IAMロールを指定します。
参考記事
本記事の解説は以上です。
ここからは、より知識を深めたい人向けに関連記事を紹介します。
類似サービス(Kinesis Data Streams)
Data Firehoseの類似サービスとして、「Kinesis Data Streams」が挙げられます。
このAWSサービスは、Data Firehoseと同様にストリームデータを扱うサービスなので、以下の記事で違いや特徴を抑えることをおすすめします。
コメント